

Types Of Machine Learning
The basic types of Machine Learning include: Supervised learning, Unsupervised learning, Reinforcement Learning, and Semi-Supervised Learning. Read this article to understand each of these types of machine learning in detail along with its uses, advantages, disadvantages, and more.
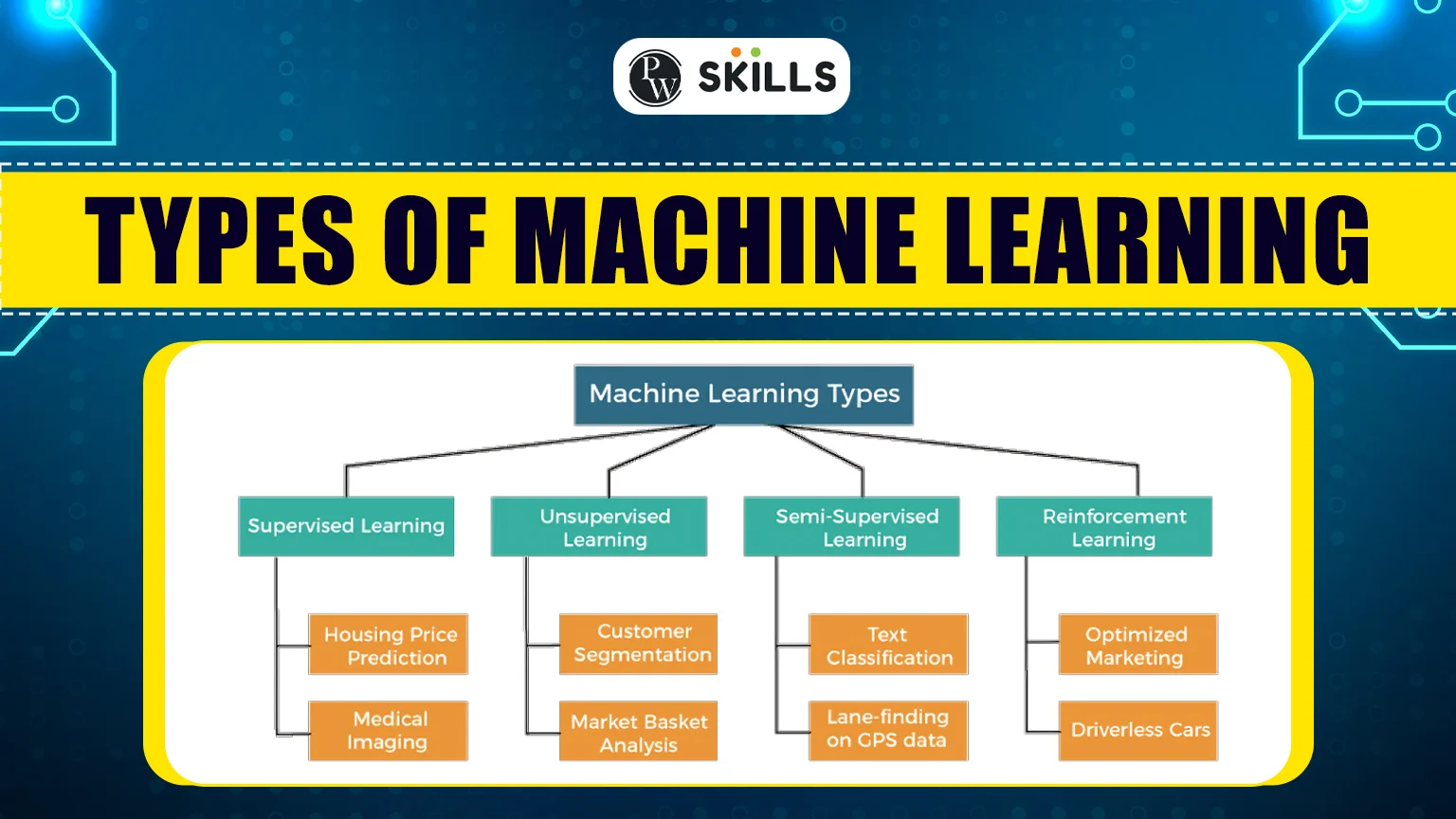
There are four primary types of machine learning that are commonly used in our day-to-day tasks. These four types include supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning. Each of these types serves different purposes and performs distinct tasks. In this article, we will explore each type in detail, discussing their uses, features, advantages, disadvantages, and applications.
Whether you're a beginner or looking to clear your understanding of machine learning, this guide will provide you with a holistic overview of these essential concepts. So, without wasting much time, let’s move further to the topic and understand the different types of machine learning better.
Types Of Machine Learning - Key Takeaways
- Understanding different types of Machine learning along with their examples.
- Getting insights into the advantages and disadvantages of different types of machine learning.
- Learning the common real-world applications of machine learning.
What Is Machine Learning?
In today's AI era, you must have heard the term "machine learning" quite a lot. Machine learning is a branch of artificial intelligence that allows computers to learn from data and make decisions or predictions without being specially programmed to do so. Instead of following a set of fixed instructions, machine learning algorithms identify patterns and relationships within the data to improve their performance over time. For example, machine learning is used in recommendations on streaming services, email spam filtering, and even in the concept of self-driving cars. It basically helps systems to adapt and get better with their usage, making it a powerful tool for solving complex problems and enhancing everyday technologies.Types Of Machine Learning
There are various types of machine learning techniques available, each with special features and uses. Some of the common types of machine learning algorithms used in our day-to-day life are as follows:- Supervised Machine Learning
- Unsupervised Machine Learning
- Semi-Supervised Machine Learning
- Reinforcement Learning
1. Supervised Learning
Supervised learning is one of the important types of machine learning algorithms, where the algorithm is trained using labeled data. This means that the data provided to the algorithm includes input-output pairs, where the correct output is already known. The algorithm learns from this data by finding patterns and relationships between the inputs and the outputs. Once the model is trained, It can predict the output for new, unseen data based on what it has learned. A simple example of this algorithm is written below that will help you to clear your concept.Example of Supervised Learning
Consider a scenario where you need to build a model to classify different types of fruits. You start by feeding the algorithm a dataset of images of fruits, where each image is labeled with the type of fruit it represents, such as apples, bananas, and oranges. The algorithm learns to recognize the features that differentiate one fruit from another, like shape, color, and size. When you later input a new image of a fruit that the algorithm has never seen before, it will use the learned patterns to predict whether the fruit is an apple, banana, or orange. This process tells how supervised learning works.Types Of Supervised Learning
The supervised learning algorithm is further classified into two main types that include: Classification Learning and Regression Learning. Let us understand each of these types in detail and see what are they used for.Classification Learning
Classification learning is a type of supervised learning where the goal is to categorize data into specific classes or groups. The algorithm is trained on a labeled dataset, where each data point is associated with a predefined category. For example, in an email spam filter, the algorithm learns to classify emails as either "spam" or "not spam" based on features like the subject line, sender, and content. The Common Algorithms used in classification learning include-- Logistic Regression
- Support Vector Machine
- Random Forest
- Decision Tree
- K-Nearest Neighbors (KNN)
- Naive Bayes
Regression Learning
Regression learning is another type of supervised learning where the aim is to predict a continuous value rather than a category. The algorithm is trained on a labeled dataset with input-output pairs, where the output is a numerical value. For example, in predicting house prices, the algorithm learns from features such as square foot area, number of bedrooms, and location. The model uses this information to predict the price of a new house based on its features. Regression is useful in many fields, including finding stock price predictions, forecasting economic trends, and many other scenarios. Some Common Algorithms Used In Regression Learning Techniques Include- Linear Regression
- Polynomial Regression
- Ridge Regression
- Lasso Regression
- Decision tree
- Random Forest
Advantages of Supervised Machine Learning
- Being trained on labeled data, these models generally have high accuracy.
- The decision-making process in supervised learning is meaningful
- This model generally takes less time than any other learning algorithm, as it generally uses labeled data and pre-trained models.
Disadvantages of Supervised Machine Learning
- It can not work on unlabeled data which can be a problem sometime.
- It can be costly as it requires special efforts to label the data first.
2. Unsupervised Learning
Unsupervised learning is also one of the most used types of machine learning technique where the algorithm is given data without any labels or predefined categories. The main goal of this algorithm is to find patterns or relationships within the data. Instead of being told what to look for, the algorithm identifies common characteristics on its own, grouping similar data points together. This is useful for discovering hidden patterns, grouping similar items, or reducing the amount of the data for further analysis. An example of this algorithm is written below for your better clarity and understanding.Example Of Unsupervised Learning
Imagine you have a dataset containing various books and their features like genre, author, number of pages, and publication year. Through clustering, an unsupervised learning algorithm can group similar books together based on these features. This will reveal a group of books that belong to specific genres or those written by the same author. Bookstores can use this information to organize their inventory more effectively or to recommend similar books to customers.Types Of Unsupervised Learning
Unsupervised learning is further classified into two main types that include: Clustering and Association. Let us understand each of these types in detail and see what are they used for.Clustering in Unsupervised Learning
Clustering is a technique in unsupervised learning where the algorithm groups data points based on their similarities. Each group, or cluster, contains data points that are more similar to each other than to those in other clusters. This method is used in various fields like- in customer segmentation, clustering can group customers with similar purchasing behaviors, allowing businesses to personalize different marketing strategies for different customers. Some of the commonly used clustering algorithms include:- K-Means Clustering algorithm
- Mean-shift algorithm
- DBSCAN Algorithm
- Principal Component Analysis
- Independent Component Analysis
Association in Unsupervised Learning
Association in unsupervised learning is a method used to discover interesting relationships or patterns between variables in large datasets. This technique identifies rules that highlight how the occurrence of one item is associated with the occurrence of another item. For example, in market basket analysis, an association algorithm can reveal that customers who buy bread are likely to buy butter also. Businesses use these association rules to optimize product placements and improve inventory management. Some of the commonly used Association rule learning algorithms include:- Apriori Algorithm
- Eclat
- FP-growth Algorithm
Advantages of Unsupervised Machine Learning
- Unsupervised learning helps to discover hidden patterns and relationships between the data.
- Useful for tasks such as customer segmentation, anomaly detection, and data exploration.
- Reduces the efforts of data labeling as labeled data is not used here.
Disadvantages of Unsupervised Machine Learning
- It is difficult to predict the quality of the model as labeled data is not used here.
- Clustering of the data may not be perfect as it is done without label.
3. Semi-Supervised Learning
Semi-supervised learning is another one of the most used types of machine learning technique that uses a small amount of labeled data and a larger amount of unlabeled data. The labeled data helps the model learn to make predictions, while the unlabeled data helps in improving the model's accuracy by providing additional information about the structure of the data. A common example of Semi-supervised learning is written below for you better understanding of the concept.Example Of Semi-Supervised Learning
Imagine you want to build a model to classify emails as spam or not spam. You have 100 labeled emails with labels of "spam" or "not spam" and 1000 unlabeled emails. In semi-supervised learning, you start by training the model on the 100 labeled emails. Once the model is built, you use it to predict labels for the 1000 unlabeled emails. These predictions are not always correct, but they provide additional information. This process helps the model to better understand the features and patterns in the emails, resulting in improved performance.Types Of Semi-Supervised Learning
There are various semi-supervised learning models each used for different purposes and having different characteristics from one another. Let us understand each of its types briefly.- Graph-based Semi-Supervised Learning: These models use graphs to represent the relationships between data points. Labels are spread from labeled to unlabeled points through these connections.
- Label Propagation: This model is used to spread the labels from labeled data to unlabeled data through a network, assuming that similar data points are close to each other.
- Co-training: This approach trains two or more different models to label the unlabeled data. Each model trains on different parts of the data, and their predictions are used to improve each other.
- Self-training: The model first trains the labeled data, and then predicts values for the unlabeled data. These new predictions are added to the training set, and the model is retrained.
Advantages Of Semi-Supervised Machine Learning
- It is better than supervised and unsupervised learning, as it works on both labeled as well as unlabeled data.
- It is suitable for large data sets.
Disadvantages Of Semi-Supervised Machine Learning
- These methods are more complex as compared to other approaches.
- Availability of labeled data is must in this algorithm, which makes it unsuitable when labeled data is not available.
- The model performance can be affected due to unlabeled data being present.
4. Reinforcement Learning
Reinforcement learning is a types of machine learning where an agent learns to make decisions by performing actions in an environment to maximize a reward. The agent starts without knowledge of the best actions and learns through the trial and error method. Every action has a consequence, resulting in a reward or punishment. Over the period of time, the agent aims to choose actions that give the highest cumulative reward. A common example of reinforcement learning is written below for your better clarity of the concept.Example Of Reinforcement Learning
Imagine training a dog to fetch a ball. The environment is your yard, the agent is the dog, and the action is fetching the ball. When the dog brings the ball back, you reward it with a treat. If the dog doesn’t fetch the ball or does something else, it doesn't receive a treat which is a negative reward. In the starting stage, the dog may not understand what to do, but over a period of time, it learns that fetching the ball leads to a treat. The dog’s goal is to get more rewards by fetching more balls. Through repeated experiences and rewards, the dog improves its fetching behavior.Types Of Reinforcement Learning
There are primarily three types of reinforcement learning techniques, each having different characteristics and each used for different purposes. Let us understand the working of each technique with the explanation given below-Q-learning
Q-learning is a simple and popular reinforcement learning technique. It uses a Q-table to store values representing the expected future rewards of taking a specific action in a specific state. The agent updates the Q-values based on the rewards received, and over time, it learns the optimal actions to take in each state to maximize its overall reward.SARSA (State-Action-Reward-State-Action)
SARSA is another reinforcement learning technique similar to Q-learning, but it updates the Q-values based on the action the agent actually takes rather than the best possible action. This makes SARSA more conservative and ensures the agent learns based on the current policy.Applications Of Machine Learning Algorithms
In this modern era, where everything is relying on technology, machine learning has various important applications in our day-to-day lives. Here are some key applications of machine learning, that will help you to understand its importance:- Machine learning algorithms can identify objects, people, and activities in images and videos, as well as can also interpret spoken language.
- It is also used for sentiment analysis, language translation, and chatbots, helping machines understand and respond to human language.
- Machine learning algorithms also assist doctors in diagnosing diseases, predicting patient outcomes, and personalizing treatment plans based on patient data.
- These Algorithms enhance fraud detection, predict trading prices, and improve credit scoring and risk management.
- These different types of Machine learning algorithms are used by companies like Amazon and Netflix to suggest products or content based on user preferences.
- Different types of machine learning algorithms are used in self-driving cars to analyze their environment, make decisions, and navigate safely.
- ML algorithms are used in virtual assistants and chatbots to provide instant support and improve customer interaction.
- Different types of Machine Learning techniques are used to create intelligent non-player characters to improve game experience.
- ML techniques also help in predicting equipment failures in industries, reducing downtime and maintenance costs.
Learn Machine Learning With PW Skills
Start your journey into the world of AI with our detailed PW Skills Generative AI And Data Science Course specially designed to serve candidates with different skill sets. Enrolling in this course will help you to learn in-demand machine learning techniques with hands-on experience through practical projects and various tools. Some of the key features of this course that make it a stand-out choice in the market include instructor-led classes, in-demand course curriculum, beginner-friendly course, 5+ capstone projects, regular doubt sessions, 100% placement assistance, alumni support, Easy EMI options on course fees, and much more. Visit PWskills.com today and start your journey with us!



🔥 Trending Blogs
Types Of Machine Learning FAQs
What are the main types of machine learning?
The main types of machine learning are supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning.
How is reinforcement learning different from supervised and unsupervised learning?
Unlike supervised and unsupervised learning, reinforcement learning focuses on learning from interactions with an environment, using rewards and penalties. It basically works on the trial and error method to find the best optimal route with maximum rewards and gets better over time.
Why is semi-supervised learning known as a hybrid approach?
Semi-supervised learning is a hybrid approach that uses a small amount of labeled data along with a large amount of unlabeled data to improve learning accuracy. Being using both - labeled as well as unlabeled data, it is said to be a hybrid approach of supervised and unsupervised learning.