

Top 10 Machine Learning Algorithms
“There are various machine learning algorithms that support many artificial intelligence tasks, such as Decision tree classifiers, Support Vector Machines, K-nearest neighbors, K-means clustering, Logistic Regression, Random Forest, and more. Let us learn more about them in this article.”

Machine Learning Algorithms can be used to identify trends and predict any events before they occur. You have the option to choose a machine learning algorithm to develop computational models of the human learning process and perform computer simulations that power up advanced Artificial intelligence. Every ML algorithm is suited to execute a particular type of task, hence, it is important to choose your machine learning algorithms wisely.
In this article, we will learn about various machine learning algorithms with their applications and features.
What Are Machine Learning Algorithms?
Machine Learning is a branch of Artificial intelligence that focuses on using data to enable AI to imitate intelligent human behaviour and gradually improve its accuracy throughout. Machine learning algorithms Machine learning algorithms are a set of procedures that allow computers to learn from data and make decisions or predictions based on specific problems.Key Takeaways
- Machine learning is a sub-part of artificial intelligence.
- Machine learning algorithms are used to power up artificial intelligence to use data and imitate intelligent human behaviour.
- There are three major ML algorithms, namely supervised learning, unsupervised learning, and reinforcement learning.
- Some more machine learning algorithms are linear regression, decision trees, random forests, logistic regression, K-nearest neighbors (KNN), Support Vector Machines (SVM), and more.
Three Major Machine Learning Algorithms
Machine learning algorithms are computational approaches that allow computers to learn from and make data-driven predictions or choices. These algorithms can be categorized into three main types supervised, unsupervised, and reinforcement learning.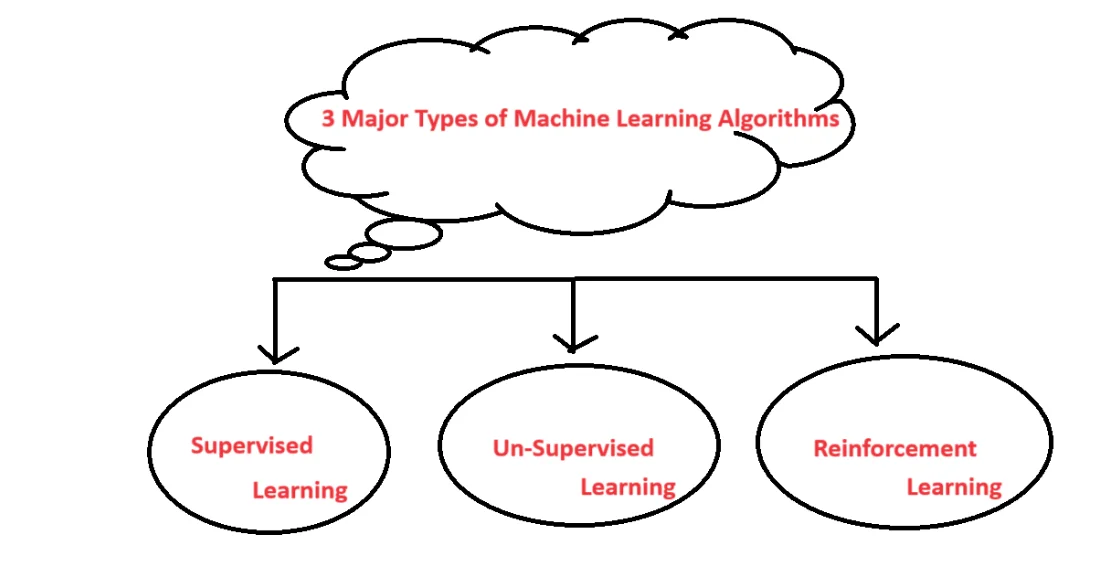
1. Supervised Learning
Supervised Learning algorithms are trained on labeled data, which means that the input data is associated with the appropriate output. The goal is for the model to learn a mapping from inputs to outputs and make accurate predictions when given new, unseen data.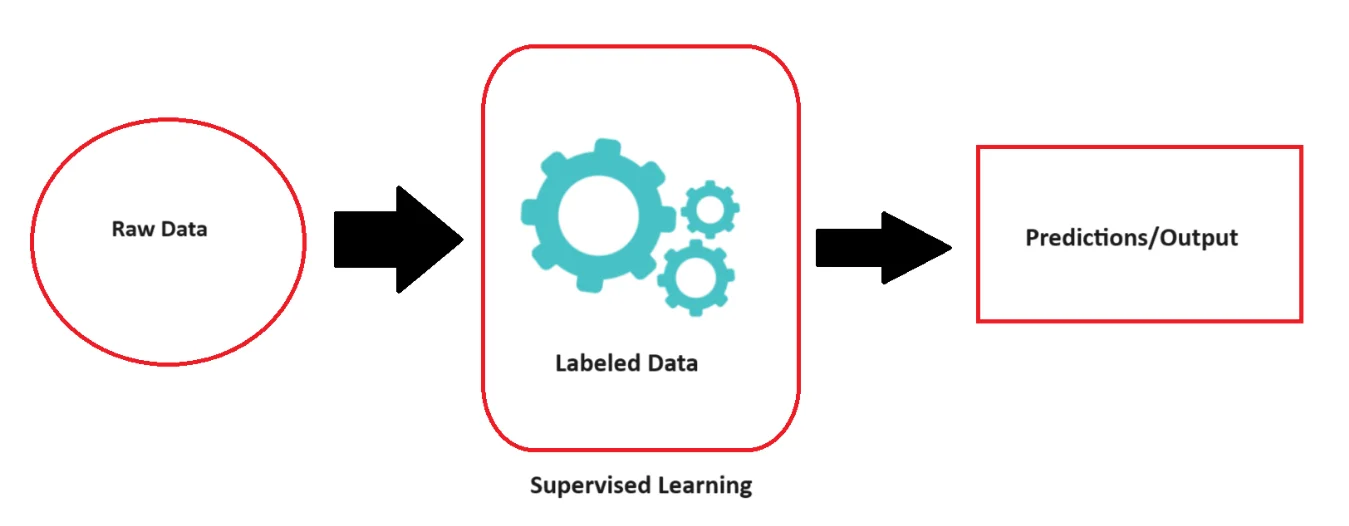 Supervised learning is used in image classification, spam detection, and medical diagnosis. Some of the machine learning algorithms based on supervised learning include linear regression, logistic regression, SVM, and Neural Networks.
Supervised learning is used in image classification, spam detection, and medical diagnosis. Some of the machine learning algorithms based on supervised learning include linear regression, logistic regression, SVM, and Neural Networks.
2. Unsupervised Learning
Unsupervised learning entails training a model on data that lacks labeled answers. It is used to draw inferences from datasets without labeled responses. The idea is to find hidden patterns or structures within the data. Unsupervised learning is used in customer segmentation, market-based analysis, and anomaly detection. Some of the machine-learning algorithms based on unsupervised learning include K-means clustering, principal component analysis (PCA), hierarchical clustering, and anomaly detection.3. Reinforcement Learning
Reinforcement learning involves training a model to make a sequence of decisions by interacting with an environment. The model learns to achieve a goal by receiving rewards or penalties based on its actions. The objective is to maximize cumulative rewards over time. It consists of an agent, an environment, an action, a state, and a reward. Reinforcement learning is used in game playing, robotics, and recommendation systems. Some of the machine-learning algorithms based on reinforcement learning include Q-learning, deep Q-networks (DQN), and policy gradient methods.Top 10 Machine Learning Algorithms
The top widely used machine learning algorithms covering a range of supervised, unsupervised, and ensemble methods are as follows:1. Linear Regression
Linear regression uses a linear equation to represent the connection between a dependent variable and one or more independent variables. It is used for predicting continuous outcomes.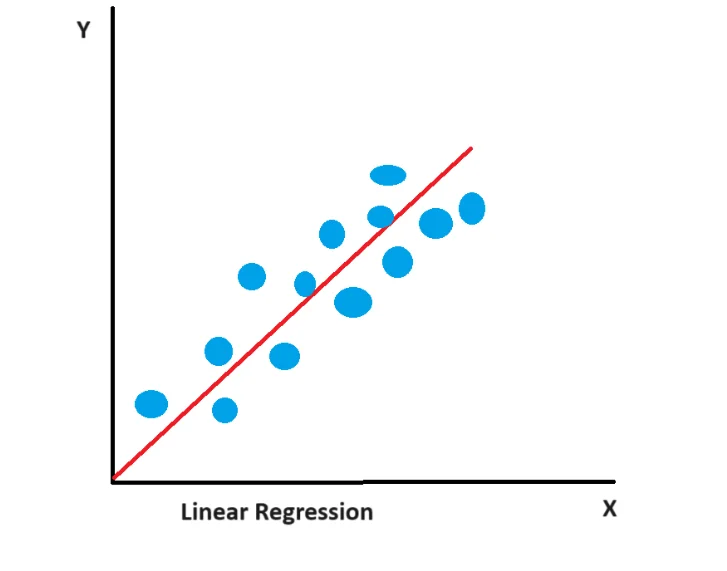 Linear regression is a statistical method that models the relationship between two or more variables by fitting a straight line to the data points. It is widely used to forecast the value of one variable using the value of another. The purpose of linear regression is to identify the best-fitting line that minimizes the difference between the observed and predicted values.
Linear regression is used in predicting housing prices, forecasting sales, and many more
Linear regression is a statistical method that models the relationship between two or more variables by fitting a straight line to the data points. It is widely used to forecast the value of one variable using the value of another. The purpose of linear regression is to identify the best-fitting line that minimizes the difference between the observed and predicted values.
Linear regression is used in predicting housing prices, forecasting sales, and many more
2. Logistic Regression
Logistic Regression is used for binary classification problems. It represents the likelihood that a given input corresponds to a specific category. Logistic regression is a statistical method used to model the relationship between a binary outcome variable and one or more predictor variables. The model estimates the odds of the outcome variable occurring based on the predictor variables. It is commonly used in research and analysis to predict the likelihood of an event and is also utilized in spam detection and disease diagnosis.3. Decision Trees
Decision trees split the data into branches based on feature values, creating a tree-like model. Each branch represents a decision rule. Decision trees are a type of model used in machine learning and data mining to make predictions by organizing a set of decision rules into a tree-like structure. Each internal node of the tree represents a decision based on a certain feature of the data, and each leaf node represents a final outcome or prediction.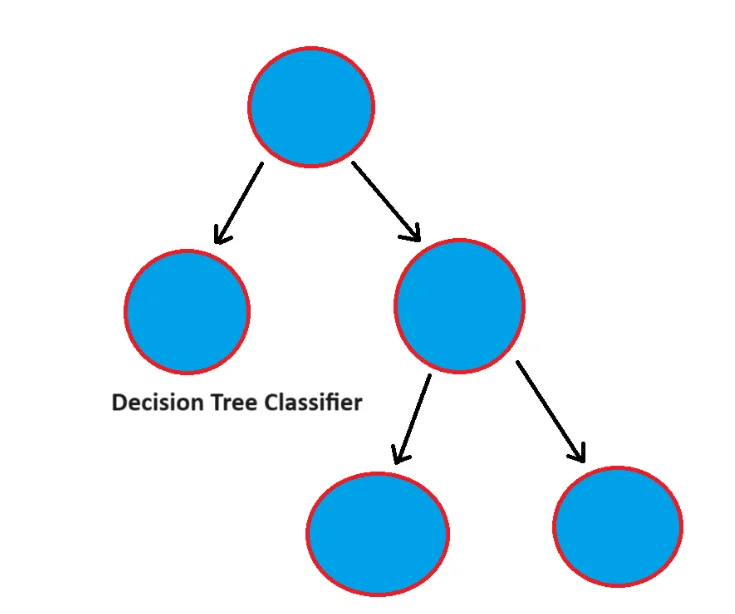 Decision trees are a popular tool for classification and regression tasks in a variety of domains, as they are easy to interpret and can handle both numerical and categorical data. These are generally used in customer segmentation, risk assessment, and many more.
Decision trees are a popular tool for classification and regression tasks in a variety of domains, as they are easy to interpret and can handle both numerical and categorical data. These are generally used in customer segmentation, risk assessment, and many more.
4. Support Vector Machines (SVM)
SVM finds the hyperplane that best separates data from different classes. It can handle linear and non-linear classification using kernel functions. Support Vector Machines (SVM) is a machine learning algorithm that is used for classification and regression tasks. It works by finding the hyperplane that best separates the different classes in the data by maximizing the margin between them. Support Vector Machines (SVM) are widely used in fields such as image recognition, text classification, and bioinformatics.5. K-Nearest Neighbors (KNN)
K-Nearest Neighbors (KNN) classifies a data point based on the majority class among its k nearest neighbors. It is simple and effective for many applications.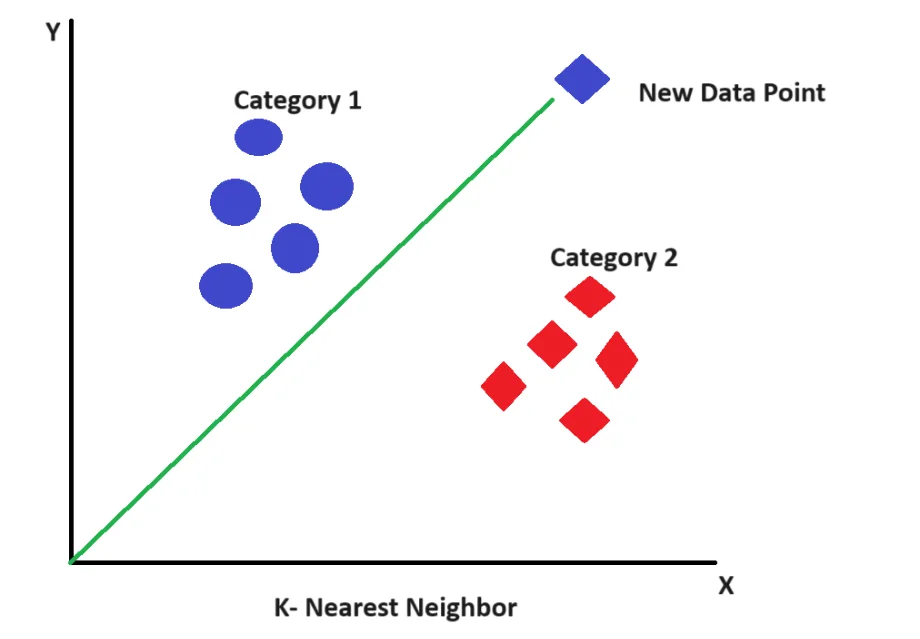 KNN is a basic machine-learning method used for classification and regression. It works because similar data points are often located close to each other in high-dimensional space. It is a type of instance-based learning where the model does not learn a specific function during training but instead uses the training data directly during the prediction phase. It is a flexible and easy-to-understand algorithm, but it may not perform well on large datasets.
KNN is mostly utilized in tasks such as handwriting recognition, recommendation systems, and many more.
KNN is a basic machine-learning method used for classification and regression. It works because similar data points are often located close to each other in high-dimensional space. It is a type of instance-based learning where the model does not learn a specific function during training but instead uses the training data directly during the prediction phase. It is a flexible and easy-to-understand algorithm, but it may not perform well on large datasets.
KNN is mostly utilized in tasks such as handwriting recognition, recommendation systems, and many more.
6. Naive Bayes
Naive Bayes classifiers are based on Baye’s theorem and assume independence between features. They are particularly effective for text classification. Naive Bayes is a simple and efficient algorithm that makes it easy to implement and computationally inexpensive. Naive Bayes is a popular technique in machine learning and data mining for text categorization, spam filtering, and sentiment analysis.7. K-Means Clustering
K-Means splits data into k clusters, with each data point assigned to the cluster with the closest mean. It is widely used for exploratory data analysis. K-means clustering is a type of unsupervised machine learning algorithm used to group data points into K clusters based on similarity. The algorithm works by repeatedly assigning data points to the nearest cluster centroid and then recalculating the centroids based on the new assignments. This process continues until the centroids no longer change significantly and data points are assigned to their final clusters. K-means clustering is commonly used for clustering and classification tasks in various fields such as pattern recognition and image analysis.8. Principal Component Analysis (PCA)
Principal Component Analysis reduces the dimensionality of data by transforming it into a set of orthogonal components, which capture the most variance in the data. Principal Component Analysis (PCA) is a statistical method used to simplify and reduce the dimensionality of a dataset while retaining as much of the variation in the data as possible. It achieves that by transforming the original variables into a new set of variables, called principal components, which are linear combinations of the original variables. The first principal component captures the most variation in the data and follows others in order. PCA is commonly used for explanatory data analysis, visualization, and dimensionality reduction in large datasets. It is also used to reduce the noise and data visualization.9. Random Forest
Random Forest combines multiple decision trees to improve accuracy and control overfitting. Each tree is trained on a random subset of the data. It is one of the most accurate with the confusion matrix percentage. Random Forest is a popular machine-learning algorithm used for both classification and regression tasks. It is a type of ensemble learning method. This helps to improve the accuracy and robustness of the model, as the individual trees are trained on different subsets of the data and may have different biases. Random Forest algorithm is generally utilized in Feature scaling, predictive modeling, and many more.10. Gradient Boosting Machines (GBM)
Gradient Boosting Machines (GBM) models sequentially, with each new model correcting errors made by the previous ones. It is highly effective for complex datasets. Gradient Boosting Machines (GBM) is a popular machine learning technique that builds a sequence of decision trees to predict the target variable. In GBM, each tree, results in an ensemble model that has high predictive accuracy. GBM is commonly used for regression and classification problems in areas such as data science, machine learning, and statistics. It is generally used in tasks such as credit scoring, fraud detection, and many more.Learn Machine Learning Algorithms with PW Skills
Master machine learning, deep learning, NLP, and various aspects of data science with our Data Science with Generative AI Course. Learn various types of machine learning algorithms as per the industry curriculum with over 5+ industry-level projects and become a certified expert in the high-demand machine learning field with PW Skills.



🔥 Trending Blogs
Machine Learning Algorithms FAQs
Q1. What is the main goal of machine learning algorithms?
Ans: Machine Learning algorithms make computers smarter and more intelligent. There are various machine learning algorithms based on the nature of the learning task and input/output type.
Q2. Why are machine learning algorithms used?
Ans: Machine Learning algorithms are used to find patterns and trends from data and generate insightful information to help you make better decisions and predictions.
Q3. What are the different types of machine learning algorithms?
Ans: The different types of machine learning algorithms are decision trees, random forest, logistic regression, linear regression, Support Vector Machines (SVM), Naive Bayes, etc.
Q4. What are the three major types of machine learning algorithms?
Ans: The three major types of machine learning algorithms are Supervised, semi-supervised, and reinforcement.