
Cluster Analysis Data Mining - Types, K-Means, Examples, Hierarchical
Cluster Analysis data mining algorithm is used to group data points into clusters or groups. It can be used to perform anomaly detection, market research, customer segmentation, image segmentation, document clustering, and much more. K-means Clustering and Hierarchical clustering are two important types of clustering.

Cluster analysis Data mining is a technique used in data analytics. While performing analytical analysis on a dataset, it is common to get overwhelmed by the large and complex datasets and the depth of the information it holds within.
Have you heard about Cluster analysis and data mining techniques in data analytics? Cluster analytics groups large groups of complex datasets into groups. In this article, let us get a detailed insight into Cluster analysis data mining techniques used in data analysis.
What is Cluster Analysis?
Cluster Analysis is a statistical method used in data analytics that groups together common groups closely associated based on various properties within a large complex dataset. Cluster analysis data mining is a crucial process used in machine learning algorithms. Cluster analysis algorithms make use of similarity metrics to group various elements together within a dataset. It is one of the most popular analytical techniques used to group various elements into different categories.
Cluster analysis algorithms make use of similarity metrics to group various elements together within a dataset. It is one of the most popular analytical techniques used to group various elements into different categories.
Cluster Analysis Data Mining Key Takeaways
- Clustering analysis uses similarity metrics to group clustered and scattered data into common groups based on various patterns and relationships existing between them.
- Clustering is used in machine learning models to group vast, scattered data elements in a dataset.
- Extrinsic and intrinsic measures must be studied and used carefully in cluster analysis data mining techniques.
- You can perform customer segmentation, market research, image segmentation, anomaly detection, and document clustering if you have knowledge of cluster analysis data mining techniques.
Why Do Cluster Analysis Techniques Need to Be Used in Data Analytics?
Cluster analysis data mining techniques eliminate confusion based on various elements and objects present within the dataset. The statistical technique of cluster analytics classifies data, objects, and observations into similar groups or clusters based on similarity metrics. Cluster analytics uses various data analytics techniques to analyze large sets of data and group them into groups based on observations of different clusters accumulated together. It involves identifying common patterns and relationships in the data that relate them to each other. This technique is used in various fields such as image and pattern recognition, healthcare, bio-departments, sociology, etc.
Cluster analytics uses various data analytics techniques to analyze large sets of data and group them into groups based on observations of different clusters accumulated together. It involves identifying common patterns and relationships in the data that relate them to each other. This technique is used in various fields such as image and pattern recognition, healthcare, bio-departments, sociology, etc.
Types of Cluster Analysis Data Mining In Data Analytics
Choosing a suitable clustering technique is very important while performing data analytics on large, complex datasets. The three major cluster analysis algorithms are mentioned below for your reference.1. K-Means Clustering
The K-Means Clustering is a cluster analysis technique that leverages centroid-based analysis using unsupervised datasets. This method of clustering arranges the dataset into clusters based on similar elements in the dataset.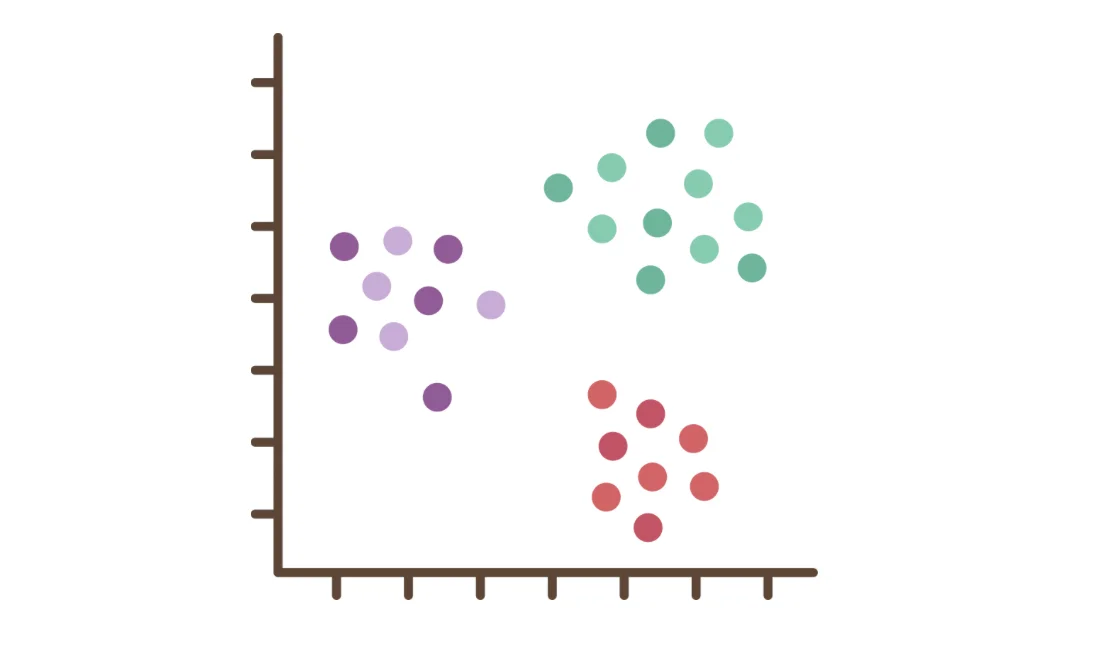 All similar groups of clusters are arranged around the centroid. Each cluster is arranged based on its distance from the centroid of the cluster in the dataset. Each data point keeps on creating new centroids until there are no further clusters left in the dataset.
All similar groups of clusters are arranged around the centroid. Each cluster is arranged based on its distance from the centroid of the cluster in the dataset. Each data point keeps on creating new centroids until there are no further clusters left in the dataset.
Features of K-Means Clustering
- Simple to implement and efficient algorithm
- Efficient algorithm in data mining techniquese.
- Work well with spherical-shaped clusters.
2. Spectral Clustering
Special Clustering is a machine learning algorithm that uses similar features to cluster data into various groups. It uses the eigenvalues of a similarity matrix derived from the data points to cluster them.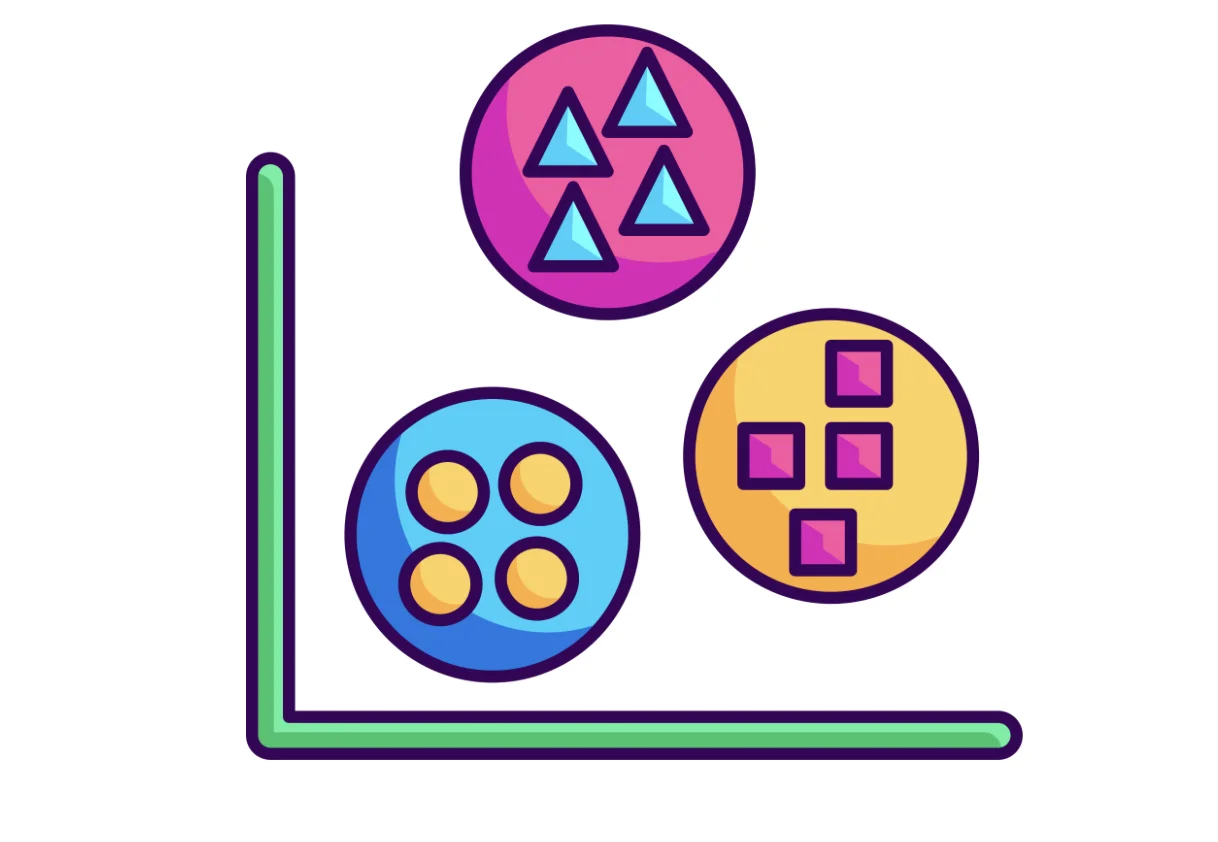
Features of Spectral Clustering
- Handles non-linear and arbitrarily shaped cluster groups
- Used for image segmentation
- Used for social network analysis and document clustering
- The Laplacian matrix is transformed into eigenvalues of eigenvectors using singular value decomposition.
3. Mean Shift Clustering
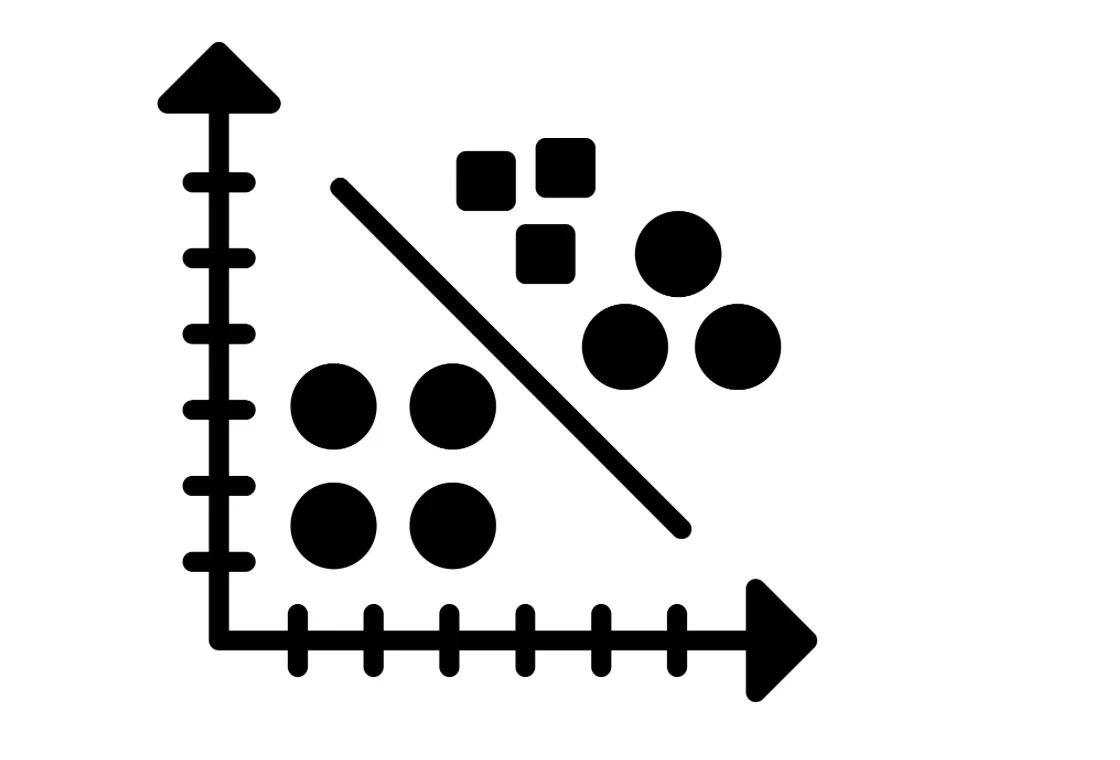 Mean shift clustering is an algorithm used in machine learning to group data points based on their densities. Each data point is shifted towards the mode (higher density) of the data points in clusters.
Mean shift clustering is an algorithm used in machine learning to group data points based on their densities. Each data point is shifted towards the mode (higher density) of the data points in clusters.
Features of Mean Shift Clustering
- This algorithm does not require a number of clusters to be specified.
- It automatically identifies the number of clusters based on mean density data.
- It is used in image segmentation, object tracking, and anomaly detection.
How Cluster Analysis Data Mining Works?
The following processes are more important in clustering data points together in a group. Check the step-by-step workings of the cluster analysis data mining algorithm below.Data Preparation
This step involves data cleaning and preprocessing the data collected. All missing values and repeated values must be handled and data is normalized to ensure that all features are on a similar scale. The next step is choosing a clustering algorithm.Choose a Clustering Algorithm
You have to be very careful before choosing a cluster analysis data mining algorithm. Each algorithm has its own features and weaknesses.- K-Means Clustering: Divides data into a specified number of clusters based on the distance between data points and cluster centroids.
- Hierarchical Clustering: Creates a hierarchy of clusters, starting from individual data points and merging them into larger clusters.
- DBSCAN: Groups together points that are closely packed together (high density) and separates clusters of low-density points.
Cluster Analysis
The chosen algorithm is then applied to the data points and all scattered data points are grouped into clusters. Once the clusters are formed, the next stage is cluster interpretation.Cluster Interpretation
After grouping clusters, we can interpret the characteristics of each character, which might involve calculating the average values of different features or using data visualization techniques to understand and present the distribution of various data points.Cluster Analysis Data Mining Examples
Let us take a simple example of the use of cluster analysis techniques in daily life.Retail Clustering Analysis Example
A retail company that wants to understand its customer base properly uses customer segmentation in cluster analysis data mining techniques to get all the information from the dataset containing all the information about its customers. The important information is age, gender, income, purchase history, and preferred brands. The data is arranged into groups or clusters based on similar characteristics. These clusters can be used to extract information about the customers to build a smart marketing strategy and product offering.Netflix Clustering Analysis Example
The scattered data based on user interaction, search history, watchlist, and history are grouped into clusters based on similar preferences. Clustering analysis is used to group users who have similar watching preferences on Netflix. Different data points, such as movie themes (action, thriller, horror, comedy), binge-watchers, watchlists, history, and other characteristics, are clustered together in groups and personalized recommendations are provided to viewers based on their preferences.Learn Data Analysis with PW Skills
Become a master in handling data with PW Skills 6 Months Data Analytics Course for beginners as well as working professionals. Learn powerful tools like Python, MySQL, Power BI, AWS, Jupyter, etc., from industry experts. Gain knowledge of Machine Learning, excel, statistics, and more within this course. Work on diverse project portfolios, practice exercises, and module-level assignments with this course.


Cluster Analysis Data Mining FAQ
Q1. What is the Cluster Analysis algorithm?
Ans: Clustering analysis uses similarity metrics to group clustered and scattered data into common groups based on various patterns and relationships existing between them.
Q2. What is K-means Clustering?
Ans: K means clustering in data analysis that uses centroid based analysis using unsupervised datasets. This method of clustering arranges the dataset into clusters based on similar elements in the dataset.
Q3. What is the Hierarchical Cluster Analysis Technique?
Ans: The hierarchical cluster analysis data mining technique creates a hierarchy of clusters, starting from individual data points and merging them into larger clusters.
Q4. What are the types of Cluster Analysis Algorithms?
Ans: K-means Clustering analysis, Spectral Clustering analysis, Mean shift clustering analysis, and Hierarchical Clustering analysis are the m+ain types of cluster analysis data mining.